
Introduction
Most internal platforms do not fail because the engineering is weak. They fail because the platform asks product teams to accept more process, more abstraction, and more waiting in exchange for a promise that life will get easier later. If teams do not trust that promise, they route around you.
That is the part of platform engineering people understate. This work is not only about Kubernetes, CI/CD, secrets, observability, or security. It is about trust, adoption, and time to value.
Over the last year at Sky, I have been building a multi tenant Kubernetes platform that spans observability, secrets management, CI/CD, security, and developer experience. Before that, I built a cloud native platform for generative AI video and image processing at Syntonym, the startup I co founded. Across both, a handful of books kept shaping the same decisions: where to add guardrails, what to simplify, what to measure, and when to say no.
These seven books did not hand me a platform blueprint. They gave me something more useful. They gave me a way to think about platforms as products that need to earn trust, remove friction, and justify their existence with real outcomes.
1. The Pragmatic Programmer by Andrew Hunt and David Thomas
The lesson I keep coming back to from this book is simple: stop trying to be clever. Be useful.
Platform teams get into trouble when they fall in love with their own architecture. Developers do not care how elegant the control plane is if their first interaction with it is a painful onboarding flow, a vague runbook, or a support ticket that bounces around three teams before anyone answers. The platform team’s job is to remove friction.
That sounds obvious, but it changes decisions. When we needed to onboard teams to Vault and connect GKE workloads to AWS S3, we could have left them with a sequence of IAM bindings, service accounts, Vault paths, and documentation. Instead, we built a CLI that collapsed the whole identity federation workflow into one guided command. Same security model, far less cognitive load.
That is the kind of pragmatism this book rewards. Not lower standards. Lower friction.
It also changed how I think about empathy. The fastest way to understand whether a platform is painful is to sit with the people using it. Join the migration. Watch the confusion in real time. Listen for the places where smart engineers hesitate. Those moments tell you more than a survey ever will.
2. Patterns of Enterprise Application Architecture by Martin Fowler
This book taught me that most platform pain shows up at the boundary.
Teams rarely hate a platform because they hate the idea of shared infrastructure. They hate it because the interfaces are inconsistent, the contracts are unclear, and every capability feels like a one off negotiation. The platform becomes a black box with support hours.
Fowler’s patterns pushed me to treat internal platform interfaces with the same seriousness we give public product APIs. Clear contracts build confidence. Predictable behaviour builds trust.
I felt this most sharply when dealing with legacy git managed Terraform for ingress and API exposure. The old model had too many hidden rules and too much state scattered across the wrong places. It worked, until it did not. We replaced that sprawl with a clearer contract through a Kong Gateway Operator, so teams could manage exposure and plugins through declarative manifests with a smaller mental model.
The platform got better, but the bigger win was psychological. Once teams can see the shape of the contract, they stop feeling like they are negotiating with infrastructure by rumour.
3. Software Architecture: The Hard Parts by Neal Ford and Mark Richards
This book is a useful antidote to architecture theatre.
In platform engineering, every serious decision creates a trade off for someone else. More isolation can mean harder debugging. Stronger policy can mean slower rollout. More flexibility can mean more operational entropy. If you hide those trade offs, teams experience them as surprise. If you make them visible, teams can at least understand the bargain.
That lesson mattered when we rolled out Cilium network policies across multi tenant GKE clusters. The security value was obvious. Better isolation, tighter default deny controls, smaller blast radius. The cost was obvious too. Debugging would get harder, and teams would need better visibility into traffic flows than they had before.
So we treated the rollout like a decision that needed to be explained, not announced. We piloted it in a non critical environment. We used Hubble so teams could actually see what the policies were doing. We introduced templates for common allow list cases. We pulled early adopters into the process before widening the blast radius.
That did not remove the complexity. It made the complexity legible. In platform work, that is often the difference between resistance and adoption.
4. Designing Data Intensive Applications by Martin Kleppmann
Kleppmann’s book sharpened one important instinct for me: assume failure, then design for recovery and visibility.
That matters just as much for platform systems as it does for product systems. Controllers reconcile because reality drifts. Schemas evolve because teams and products evolve. Telemetry matters because a platform you cannot observe is a platform you cannot improve.
This book reinforced several patterns that now feel non negotiable in my work. Design for schema evolution. Prefer reconciliation over wishful thinking. Treat audit trails as part of the product. Separate workloads by what they need from the system, not by habit. Use event driven scaling when the workload actually behaves like an event driven system.
The practical effect is that platform architecture becomes calmer under pressure. You stop designing around happy paths and start designing around the fact that networks break, dependencies wobble, and real workloads rarely behave as neatly as architecture diagrams suggest.
5. Refactoring by Martin Fowler
Most platforms do not collapse in one dramatic failure. They get slower, stranger, and harder to change.
That is why this book matters so much in platform work. A platform accumulates wrappers, exceptions, old assumptions, and once sensible decisions that no longer fit the current shape of the organisation. If you only ever add new capability, the user experience eventually turns into archaeology.
What Fowler gives you is discipline. Improve the system in small steps. Protect behaviour. Let understanding drive change.
I have seen this pay off repeatedly. We replaced complex Terraform modules for observability onboarding with simpler declarative configuration. We moved ingress management away from team specific Terraform sprawl towards clearer operator driven manifests. We simplified service account federation workflows with tooling that removed repeated manual steps. None of those changes were glamorous. All of them made the platform easier to use and easier to maintain.
The measurable result was not trivial. CI/CD pipeline times dropped from about sixty minutes to ten. Just as importantly, teams stopped treating the platform as something fragile that only a few people were allowed to touch.
6. The Lean Startup by Eric Ries
This is the book that reminds me platform teams can waste just as much effort as product teams.
It is easy to spend months building an internal capability that feels strategically important, only to learn that nobody really wanted it in that form. Platform teams are especially vulnerable here because our users are nearby, polite, and usually too busy to tell us early that something is awkward.
The Build, Measure, Learn loop is extremely useful in this context. Start with a narrow slice for a few teams. Define what success looks like before rollout. Measure adoption, onboarding time, support burden, and repeat usage. If the feature creates confusion, simplify it. If the value is not showing up, stop pretending it will magically emerge at scale.
That mindset changed how I think about new platform capabilities. A gateway operator, a self service workflow, a new policy model, or an observability feature should not be treated as complete because it shipped. It is only complete once you know whether it reduced friction for real teams in real conditions.
Internal platforms need product discipline just as badly as customer facing software. Sometimes more.
7. Platform Engineering by Camille Fournier and Ian Nowland
This is the book that gave language to something I had been doing instinctively for years.
Before reading it, I could explain the technical quality of our platform. I could talk about security posture, architectural consistency, deployment safety, and operational maturity. What I found harder was explaining value in a way that mattered to engineering leadership. Why should a company invest in a dedicated platform team instead of leaving every product team to manage its own stack?
Fournier and Nowland answer that directly. The platform is not just infrastructure. It is a product. That means user research, roadmap choices, adoption metrics, support cost, and return on investment all belong inside the job description.
That framing changed how I described our CI/CD Runway system. It stopped being “a standardised pipeline” and became what it actually was: a user facing product that reduced deployment complexity, shortened time to first deploy, and made the golden path measurable.
The book also sharpened how I think about platform maturity. The Pioneers, Settlers, Town Planners model is useful because platform teams live in the tension between proven technology and messy organisational reality. When we adopted Cilium, we were operating in pioneer territory. There was uncertainty, operational learning, and a real chance of getting it wrong. When we standardised ingress through Kong Gateway Operator, that was settler work. The technology was proven. The challenge was turning it into something governable and easy to use at scale.
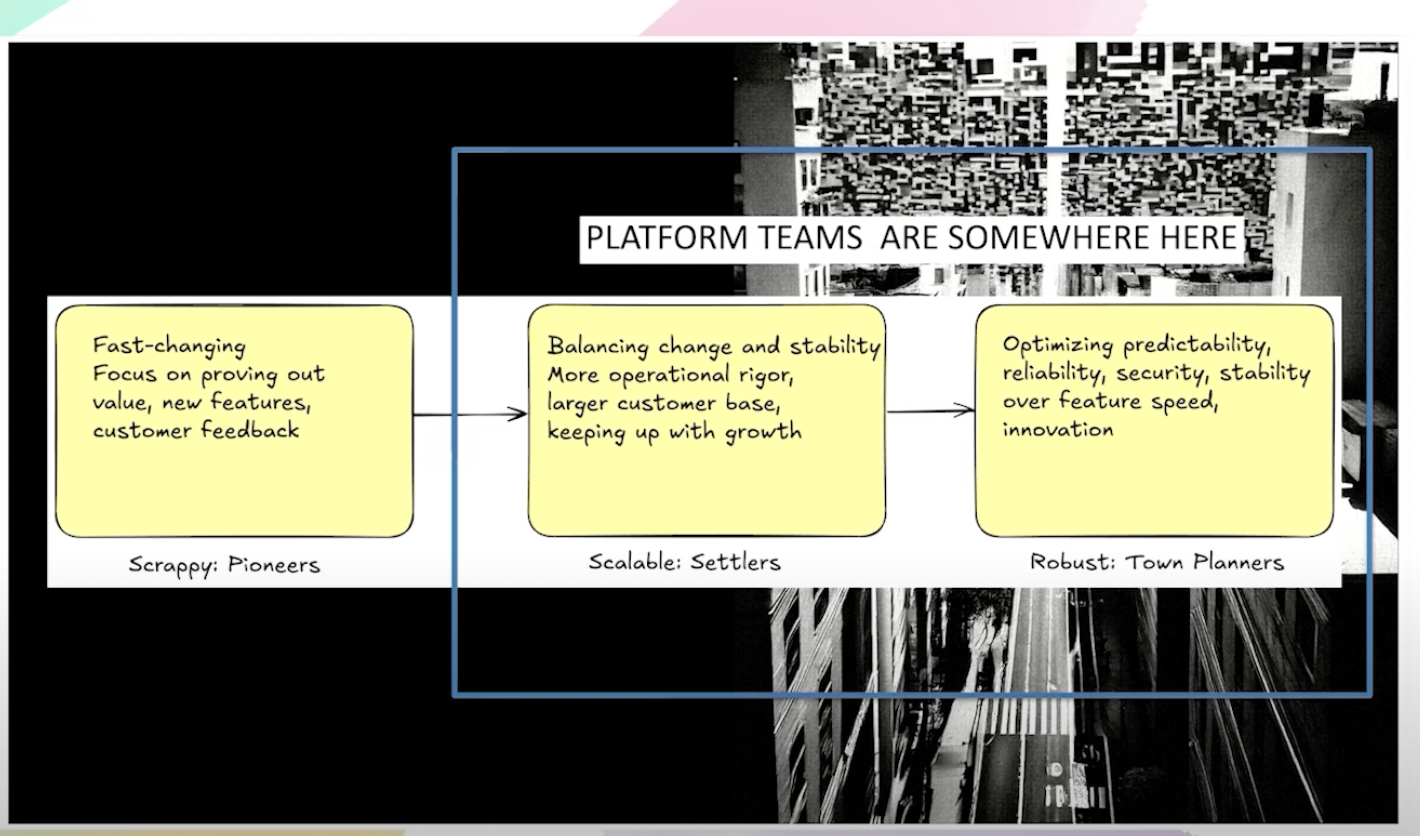
That distinction matters. If you treat pioneer work like routine platform plumbing, you create avoidable risk. If you treat settled capabilities like research projects, you waste everyone’s time.
Today, we track onboarding time, feature adoption, support burden by capability, and golden path usage across tenant teams. That data is now part of roadmap planning and part of the case for continued platform investment. Once you can show that a capability saves weeks of onboarding or cuts deployment friction materially, the platform stops sounding like an internal cost centre and starts looking like what it is: a force multiplier.
What These Books Changed in My Work
Taken together, these books pushed me towards a much stricter standard for platform work.
Build interfaces that people can understand. Remove repetitive pain without hiding important truth. Make trade offs visible early. Treat telemetry, auditability, and recovery as product features. Refactor before complexity hardens into policy. Measure whether teams are actually better off after you ship.
That last point is the one I care about most now. A platform is only good if good engineers choose to use it again.
Final Thoughts
Books do not build platforms. Teams do. But the right books can sharpen your instincts before you make expensive mistakes in production.
These seven shaped mine. They helped me stop treating platform engineering as an infrastructure exercise and start treating it as a product discipline with technical depth, human consequences, and measurable outcomes.
If you are building an internal platform now, that is the shift I would recommend making first. Ask less often whether the platform is technically impressive. Ask more often whether it is trusted, adopted, and worth repeating.
Additional Resources
The Pragmatic Programmer, The Lean Startup, and Platform Engineering
~/whoami
I'm a software engineer who cares a lot about building things people genuinely enjoy using. Outside work, you will usually find me on the water, running, or chasing Formula 1 around the world. Thoughts are my own on Still Twitter, Bsky, and LinkedIn.